


香港轻量云低延迟不限流量,外贸站群稳定运行





多模态 RAG(Retrieval-Augmented Generation)是在传统文本 RAG 基础上整合视觉、听觉等多种信息源,从而提供更丰富、准确且上下文相关的回答。这一技术极大地拓展了人工智能系统的应用范围与实用性,使其能够处理和理解图像、音频、视频等多类型数据,而不再局限于文本。今天我将深度解析多模态RAG的实践路径及其工作原理,希望对你们有所帮助。
多模态 RAG 的核心思想是将 RAG 的检索与生成机制扩展至多模态语境,主要包括以下三个方面:
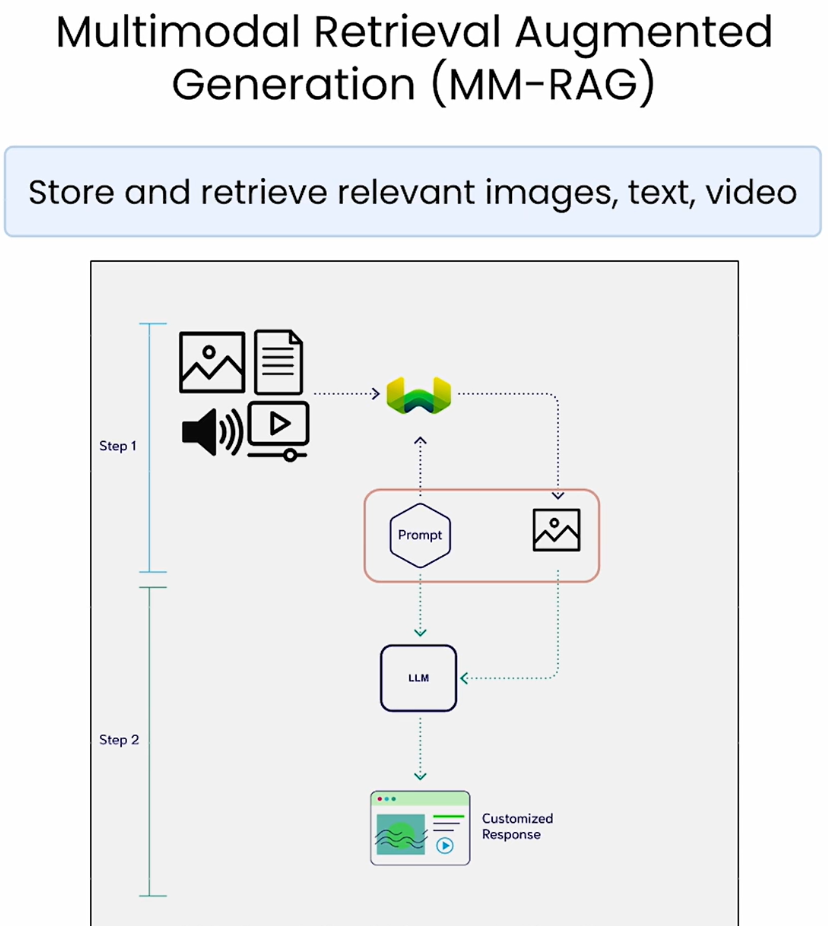
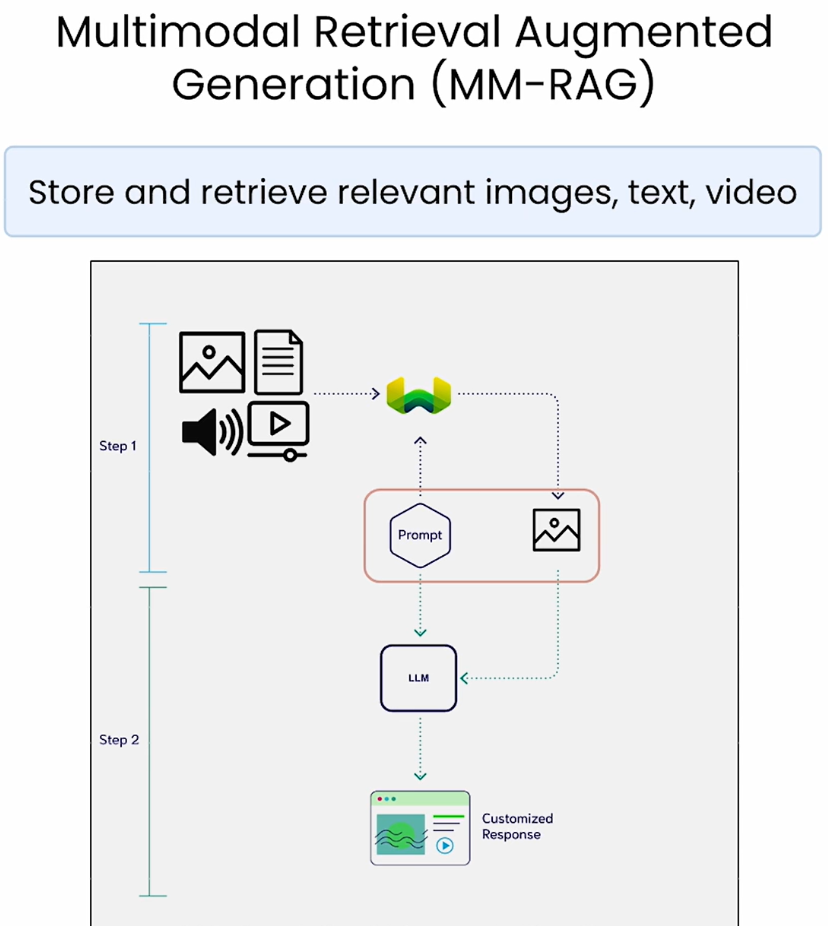
实现多模态 RAG 系统,主要依赖以下三类技术组件:
多模态编码器 用于将不同模态原始数据转换为统一语义空间中的向量表示。常用模型包括 CLIP、ALBEF、VinVL 等。具体地:
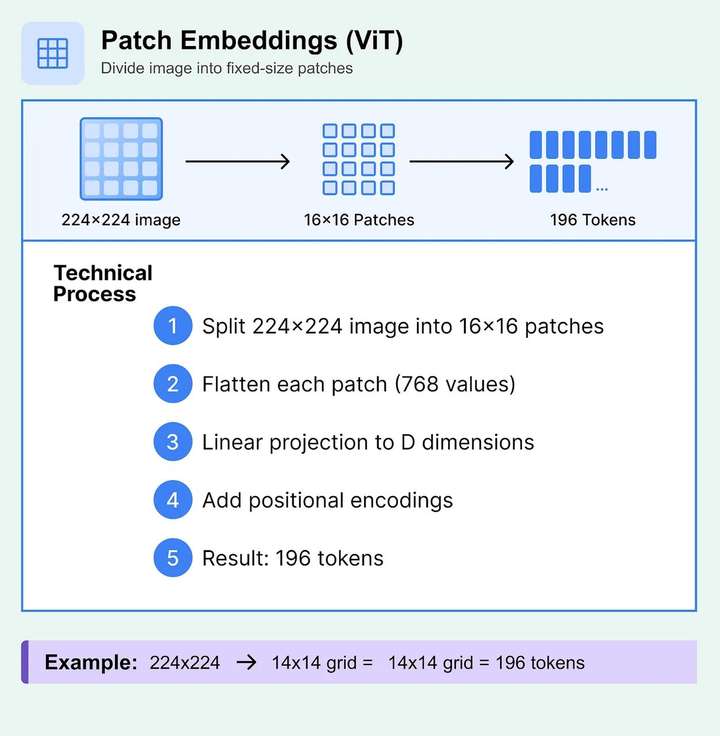
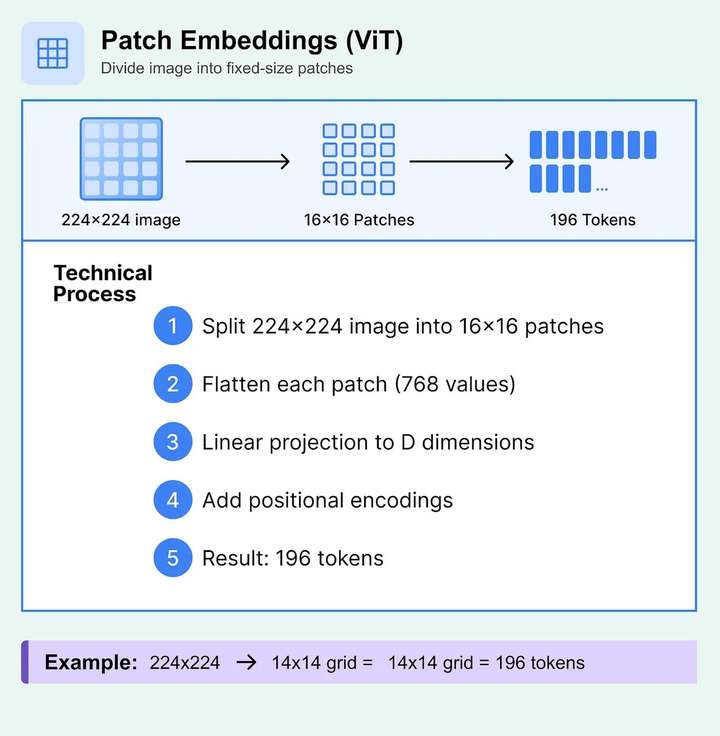
多模态检索系统 基于统一向量空间实现跨模态的相似性搜索,支持高效检索多模态内容。
多模态生成模型 能够理解并生成融合多模态信息的回答,典型模型如 Flamingo、BLIP-2、GPT-4V 等。
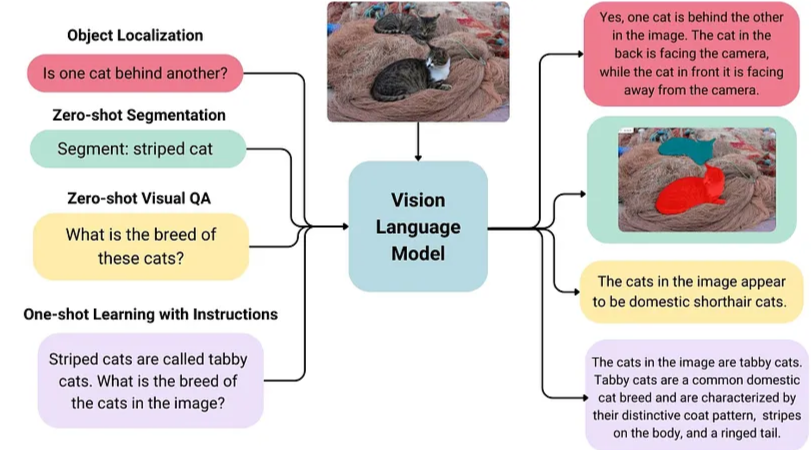
多模态 RAG 的工作流程可划分为三个阶段:
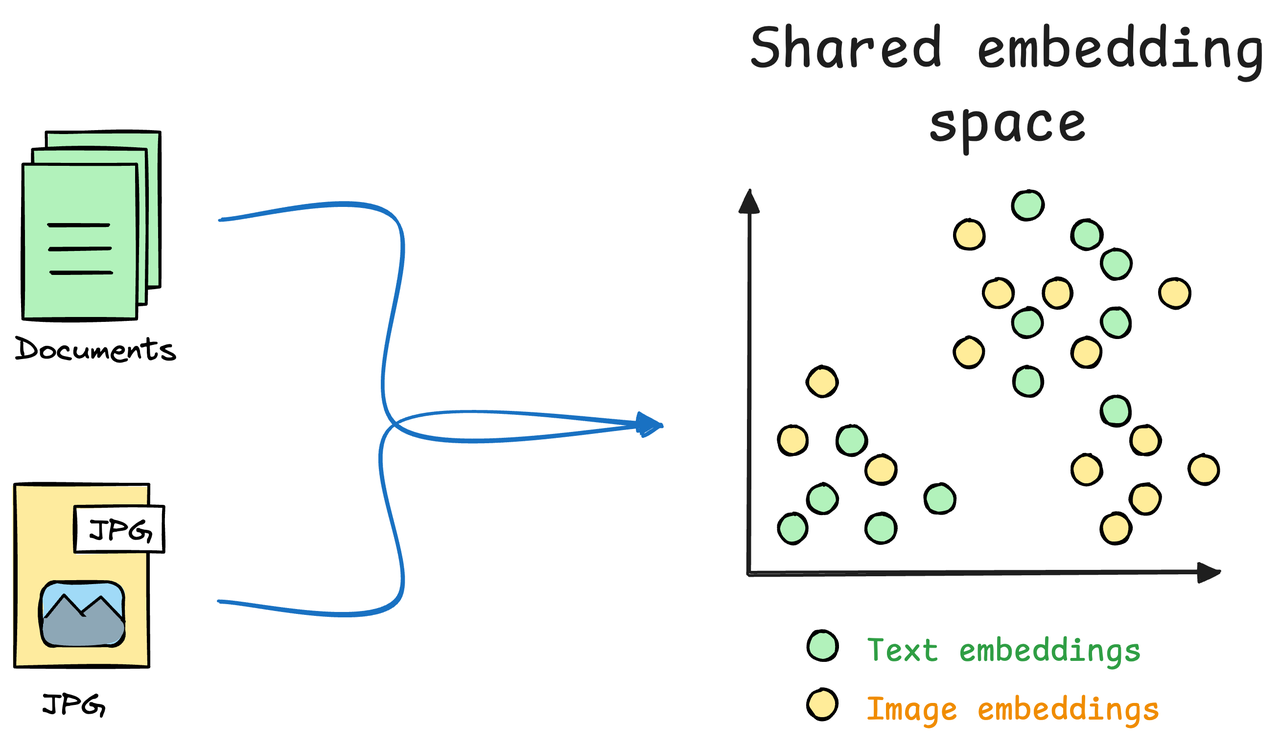
多模态 RAG 的发展仍面临多项关键挑战:





 售后客服
企业微信
售后客服
企业微信















